概率分布就像3D眼镜。它们使熟练的数据科学家能够识别完全随机变量中的模式。
在某种程度上,大多数数据科学或机器学习技能都是基于对数据概率分布的一些假设。


这使得概率知识成为统计学家构建工具箱的基础。如果你正在考虑如何成为一名数据科学家,那么这就是* * *的一步。
废话少说,让我们开门见山吧!
什么是概率分布?
在概率论和统计学中,随机变量是一个可以随机取不同值的变量,比如“我看到的下一个人的身高”或者“我下一碗拉面里厨师的头发量”。
给定一个随机变量x,我们想描述它取哪个值。更重要的是,我们想描述一个变量取某个值X的可能性。例如,如果X是“我女朋友有多少只猫”,那么这个数字可能是1,甚至是5或10。
当然,猫的数量不能是负数。
因此,我们希望用一种清晰的数学方法来表示变量X可以取的每一个可能的值和一个事件的可能性(X=x)。
为此,我们定义了一个函数P,使得P(X=x)是变量X的值为X的概率,
我们也可以使用P(X x)或P(X x)来代替离散值。这非常重要。
P是变量的密度函数,代表变量的分布。
随着时间的推移,科学家已经意识到自然界和现实生活中的许多事物往往是相似的。变量共享一个分布或具有相同的密度函数(或相似的函数)。
要使p成为实密度函数,需要一些条件。
离散与连续随机变量分布
离散随机变量
一、伯努利概率分布
二、均匀概率分布
例如,当我们投掷硬币时,如果我们说
但是请注意离散集合不一定是有限的。
但是请注意离散集合不一定是有限的。
几何分布,事件发生的为P,* * *成功的概率在k次测试后获得:
k可以取任意正整数。
请注意,所有可能值的概率之和仍然是1。
If
If
X可以取什么值?我们知道负数在这里没有意义。
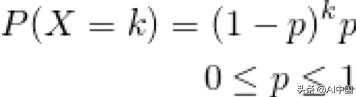 @
@
但是,如果你说的是1毫米而不是1.1853759毫米.或者类似的事情,我要么怀疑你的测量技能,要么你的测量报告是错误的。
连续随机变量可以取给定(连续)间隔内的任何值。
如果X是连续随机变量,f(x)用来表示X的概率分布密度函数。
用P(a×b)来表示X位于值a和b之间的概率。
为了获得X取任意给定实数a的概率,X的密度函数需要从a到b积分。
既然你知道概率分布是什么,让我们学习一些最常见的分布!
三、正态概率分布
四、对数正态分布概率分布
它意味着一个二进制事件:“此事已发生”对“此事未发生”,并且将值P作为指示事件发生概率的唯一参数。“伯努利分布”随机变量B的密度函数为:其中B=1表示事件发生,B=0表示事件未发生。
请注意,这两个概率加起来等于1,所以不能有其他值。
五、指数概率分布
均匀随机变量有:离散随机变量和连续随机变量两种。
离散均匀分布将取一组(有限的)值S,并为每个值分配1/n的概率,其中n是以S表示的元素数,
数据科学中的指数概率分布
Dice是一个非常典型的离散均匀随机变量。典型的骰子有一组值{1,2,3,4,5,6},元素的数量为6,每个值出现的概率为1/6。
连续均匀分布仅采用两个值A和B作为参数,并在它们之间的间隔内为每个值分配相同的密度。
这意味着Y在一个区间(从C到D)取值的概率与其相对于整个区间(从B到A)的大小成正比。
因此,如果Y在A和B之间均匀分布,那么
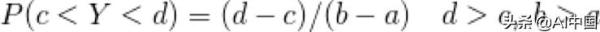 @
@
因此,如果Y是1和2之间的均匀随机变量,
p(1x 2)=1,p(1x 1.5)=0.5@
Python随机包的随机方法对0和1之间均匀分布的连续变量进行采样。
有趣的是,可以证明给定均匀随机值生成器和一些微积分,任何其他分布都可以被采样。
结论
正态分布变量在自然界中非常常见。它们是正常的,这就是这个名字的由来。
如果你召集你所有的同事,测量他们的身高,或者称他们的体重,然后用结果绘制直方图,结果很可能接近正态分布。
如果你从任何随机变量中抽取样本,对这些测量值求平均值并重复多次,平均值也将呈正态分布。这个事实非常重要。它被称为统计学的基本定理。
正态分布变量:
在大多数情况下,如果你测量任何经验数据并且它是对称的,你通常可以假设它是正态分布。
例如,如果你掷骰子并将结果相加,你将得到正态分布。
对数正态概率分布是一种罕见的正态概率分布。
如果变量Y=对数(X)遵循正态分布,那么变量X称为对数正态分布。
在直方图中,对数正态分布是不对称的,标准差σ越大,分布越不对称。
我认为对数正态分布值得一提,因为大多数基于货币的变量都是这样的。
如果你观察任何与货币相关的变量的概率分布,比如
它们通常不是正态概率分布,而是更接近对数正态随机变量。
(如果你能想到你在工作中遇到的任何其他对数正态变量,请在评论中评论它们!尤其是金融以外的东西)。
指数概率分布也随处可见,这与泊松分布概率的概念密切相关。
泊松分布直接抄袭维基百科。它是“一个事件以恒定的平均速率连续独立发生的过程”。
这意味着,如果:
泊松分布可能是发送到服务器的请求、发生在超市的交易或在湖里钓鱼的鸟。
想象一个频率为λ的泊松分布(例如,事件每秒发生一次)。
指数随机变量模拟下一个事件发生后所需的时间。
有趣的是,在泊松分布中,事件可以在任何时间间隔内发生在0到∞之间的任何地方(概率降低)。
这意味着无论你等多久,发生事故的可能性都不是零。这也意味着它可能在很短的时间内发生多次。
在课堂上,我们经常开玩笑说公交车到达是泊松分布。我认为当你向一些人发送WhatsApp消息时,响应时间也符合这个标准。
λ参数调整活动的频率。它将事件实际发生所需的预期时间集中在某个值上。
这意味着如果我们知道每隔15分钟就有一辆出租车经过我们的街区,即使理论上我们可以永远等下去,我们也很可能等不到30分钟。
这是指数随机变量:的密度函数
假设你有一个变量样本,想知道它是否可以用指数分布变量建模。
λ参数可以很容易地估计为采样值平均值的倒数。
指数变量非常适合建模任何罕见但巨大的异常值。
这是因为它们可以取任何非负值,但以较小的值为中心,频率会随着值的增加而降低。
在特别重的样本中,您可能想要估计λ中值而不是平均值,因为中值对异常值更稳健。在这一点上,你的兴趣可能不同,所以你对此有所保留。
总之,作为一名数据科学家,我认为学习基础知识非常重要。
概率和统计也许不像深度学习或无监督机器学习那样华而不实,但它们是数据科学和机器学习的基石。
根据我的经验,在不知道机器学习模型遵循哪种分布的情况下,提供具有特征的机器学习模型是一个糟糕的选择。
记住指数分布和正态分布的普遍性以及罕见的对数正态分布也是很好的。
当训练机器学习模型时,了解它们的特性、用途和性能将会扭转这种模式。在进行任何类型的数据分析时,最好记住它们!
极牛网精选文章《数据科学家都应该知道这5个概率分布》文中所述为作者独立观点,不代表极牛网立场。如若转载请注明出处:https://geeknb.com/3864.html
 微信公众号
微信公众号  微信小程序
微信小程序 