

我第一次听到沙普利值是在学习模型可以解释的时候。我知道SHAP,这是一个框架,可以更好地理解为什么机器学习模型是这样工作的。事实证明沙普利值已经存在了一段时间,它们起源于1953年的博弈论领域,旨在解决以下情况:
一组具有不同技能的参与者相互合作以获得集体奖励。那么,如何在团队中公平分配奖励呢?
当一个“旧”概念被应用到另一个领域,如机器学习时,它如何获得新的应用是非常有趣的。在机器学习中,参与者是你输入的特征,而集体支出是模型预测。在种情况下,沙普利值用于计算每个单独特征对模型输出的贡献。
如何计算沙普利值?大多数时候,你会在文献中看到这个等式:

让我们把它分解。在联盟游戏(前面描述的场景)中,我们有n个玩家。我们还有一个函数V,它给出这些参与者的任何子集的值,也就是说,S是N的子集,然后v(S)给出这个子集的值。因此,对于一个联合游戏(n,v),我们可以用这个方程来计算玩家1的贡献,即沙普利值(Shapley value)。
我不知道你现在在想什么,但是当我第一次遇到这个等式时,我的第一反应是这样的:

我很难理解为什么它看起来像这样。经过一段时间的学习,我终于开始有了一些了解。那么,让我们开始吧!
嗯,我们要做的第一件事是重写初始方程:

乍一看,这个公式似乎不容易,但请不要担心。很快,我将分解方程的不同部分来理解它们,但是我们也可以定义一个特定的场景,并且我们可以用它来降低所有部分的抽象性。
假设我们经营一家砖厂。我们的一个制作团队由四个人组成:阿曼达、本、克莱尔和唐(从现在开始,我会用他们名字的第一个字母称呼他们)。他们试图每周一起生产x块砖。由于我们的工厂运转良好,我们有奖金给团队成员。然而,为了让我们公平地做到这一点,我们需要找出每个人每周为x块砖的生产贡献多少。
最困难的是,我们有几个因素会影响团队生产砖块的数量。其中之一是团队规模,因为团队规模越大,生产的砖块就越多。另一种可能性是团队成员之间的合作程度。问题是我们无法以有意义的方式量化这些影响,但幸运的是,我们可以使用沙普利值来避免这个问题。
我们现在已经定义了我们的玩家(甲、乙、丙、丁)和他们玩的游戏(制砖)。让我们从计算产生的x块可以归属于唐开始,也就说,计算d的沙普利值。如果我们把它和沙普利值公式的参数联系起来,我们会得到:

所以d是我们的一号队员,整个n组由所有四名队员a、b、c和d组成。让我们先看看沙普利值公式的这一部分:

也就是说,我们需要把我们的队员排除在我们现在关心的人之外。然后,我们需要考虑所有可能的子集。所以如果我们把d排除在组外,我们只有{A,b,C}。从这个剩余的组中,我们可以形成以下子集:


我们可以构建剩余团队成员的总共8个不同子集。一个子集是空集,也就是说,它没有成员。现在让我们把注意力转向这一部分:

这是我们沙普利值的一个基本概念的应用:增加游戏中玩家1的边际价值。因此,对于任何给定的子集,当包含播放器1时,我们将比较它的值和它的值。通过这样做,我们得到了将玩家1添加到子集的边际价值。
我们把它和我们的例子联系起来,看看我们是否把D加到8个子集中的每一个上,每周生产多少块砖。我们可以直观地将这8个边值表示为:

你可以把每种情况看作是一个不同的场景,我们需要观察它,以便公平地评估数据对整个生产的贡献。这意味着我们需要观察如果没有人工作(即空组)将生产多少砖,并将它们与只有D工作时的情况进行比较。我们还需要观察AB生产的砖的数量,并将其与AB生产的砖的数量和D在所有8组中可以生产的砖的数量进行比较。
嗯,我们现在知道我们需要计算8个不同的边值。沙普利值方程告诉我们,我们需要把它们加在一起。然而,在我们这样做之前,我们仍然需要调整每个边际值,从等式的这一部分可以看出:
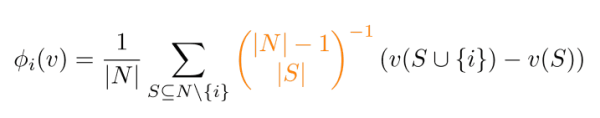 @
@
它计算除了玩家1之外,所有剩余团队成员的子集可以被安排多少。或者换句话说:如果你有| N |-1个玩家,你可以用他们组成多少个| S |大小的团体?然后我们将这个数字除以玩家1对所有组| S |的边际贡献。
在我们的场景中,| N |-1=3,也就是说,当我们计算D的沙普利值时,这些是剩余的团队成员。在我们的示例中,我们将使用等式的这一部分来计算我们可以形成多少个大小为0、1、2和3的组,因为这些只是我们可以用剩余成员构造的组大小。因此,例如,如果| S |=2,那么我们可以构造3个不同的大小为2的组:AB、BC和ca。这意味着我们应该对8个边值中的每一个应用以下比例因子:

让我们想想为什么要这样做。我们想知道D对团队的总产出有多大贡献。为了做到这一点,我们计算了他对我们能组建的每组团队的贡献。通过添加这个比例因子,我们平均了其他团队成员对每个子集大小的影响。这意味着,当我们将D添加到0、1、2和3个规模的团队中时,我们可以获取这些团队的平均边际贡献。
好吧,我们快完成了。我们只有沙普利值方程的最后一部分要分解,这应该很容易理解。

我们需要应用所有的边缘值,然后才能对它们求和。我们必须把他们从玩家总数中分离出来。
我们为什么要这样做?如果我们看看砖厂的例子,我们已经平均了其他团队成员对每个子集大小的影响,所以我们可以计算出D对大小为0、1、2和3的组的贡献。最后一个难题是平均群体规模的影响,也就是说,D贡献多少与群体规模无关。
我们现在终于可以计算出D的沙普利值了,我们已经观察到他对团队所有不同子集的贡献。我们还对团队成员和团队规模的影响进行了平均,这最终使我们得以计算:

数学符号更多的是一种图形解释,而不是数学解释(这是我在脑海中的想象)
在这里,我们得到了D的沙普利值。在我们为团队其他成员完成这项工作后,我们将知道每个人对每周生产的x块砖的贡献,这样我们就可以在所有团队成员之间公平地分配奖金。

此时,我希望你能更好地理解沙普利的价值观。很酷的是,我们不需要知道价值函数V的内部工作原理,我们只需要观察它为不同子集提供的价值,我们可以从参与游戏的玩家那里得到这些价值。
这是沙普利价值观背后真正的力量和吸引力。然而,这是有代价的。对于一组n个参与游戏的玩家,你需要分析2 n个子集来计算沙普利值。
有一些方法可以使计算更加实用。在导言中,我提到了沙普利框架。它的主要优点是SHAP将沙普利值应用于机器学习时,可以更有效地计算沙普利值。
极牛网精选文章《机器学习中的 Shapley 值怎么理解?》文中所述为作者独立观点,不代表极牛网立场。如若转载请注明出处:https://geeknb.com/2775.html
 微信公众号
微信公众号  微信小程序
微信小程序 
评论列表(1条)
鞭擗入里!感谢