Hadoop分布式文件系统(HDFS)旨在适用于运行在商用硬件上的分布式文件系统。


HDFS可以提供高吞吐量的数据访问,非常适合大规模数据集的应用。HDFS是大数据生态系统中最重要的底层分布式文件系统。它的稳定性关系到整个生态系统的健康。
本文介绍了与HDFS相关的重要监测指标,并分享了这些指标背后的思考。
一、HDFS监控挑战
HDFS是Hadoop生态的一部分。监控方案不仅需要应用HDFS,还需要应用纱线、糖化血红蛋白、蜂箱等其他成分。但也需要应用
HDFS应用编程接口提供的更多指标。有些指标不需要实时收集。但是,当发生故障时,快速获取
Hadoop相关组件的日志非常重要。如问题定位、审计等
监控方案不仅能满足监控本身,而且故障定位所涉及的指标应涵盖
二、Hadoop监控方案
Hadoop监控数据的采集是通过超文本传输协议接口或JMX进行的。事实上,CDH和安巴里是被广泛使用的主要产品。此外,还有一些工具,例如Jmxtrans和Hadoop出口商(针对普罗米修斯)。
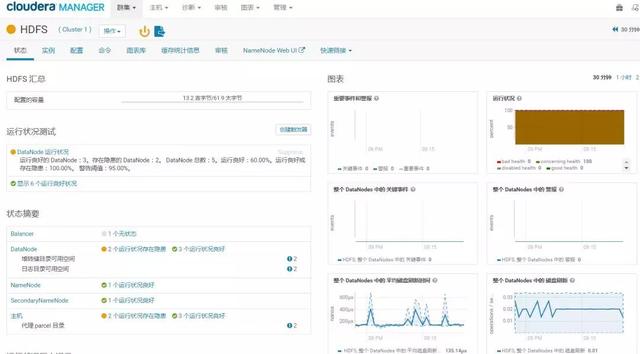
CDH是一个开源Hadoop生态组件管理工具,集成了部署、监控和操作。它还提供收费版本(比免费版本更多的功能,如数据备份和恢复以及故障定位)。CDH提供的HDFS监控界面经验丰富。它是经过深入探索后HDFS监测指标的集中,如HDFS容量、读写流量和时间消耗、数据节点磁盘刷新时间消耗等。
CDH提供的HDFS监控界面
Ambari类似于CDH,也是一个开源工具,但扩展性更好。此外,它的信息可以从不同的维度显示,如机器、组件和集群,这与操作和维护工程师的使用习惯很接近。
 @
@
安巴里提供的HDFS监测接口
如果CDH或安巴里用于HDFS监测,也存在实际问题:
相对应的Hadoop和相关组件版本无法自定义以满足大规模HDFS集群的实际监控要求
其他工具,如Jmxtrans,目前无法很好地适应Hadoop,因此,实际监测方案选择如下:
Collection: HadoopExporter、Hadoop HTTP API(注:HDFS主要调用http://{domain}:{port}/jmx)日志:通过ELK收集和分析存储:Prometheus演示: 色调警报:Dock京东云警报系统@
三、HDFS监控指标
1、主要指标概览
HDFS主要监测指标概述
2、黑盒监控指标
基本功能
文件。在文件的整个生命周期中是否有任何异常功能,主要是监视文件的创建、查看、修改和删除。
查看时,您需要校对内容。有一种方法可以在文件中写入时间戳,并在查看时校对时间戳。这样,你可以根据时差来判断是否加班。
请记住确保完整的生命周期,否则,监控生成的大量临时文件可能会导致HDFS群集崩溃
3、白盒监控指标
1)错误
块丢失量
收集项目:丢失块
如果块丢失,则意味着文件已被损坏。因此,有必要在区块丢失之前提前预测区块丢失的风险(通过监测未充分复制的区块来判断)。
不可用数据节点占比
Collection Items:
IsGoodTarget在BlockPlacementPolicyDefault.java定义了选择数据节点的策略,其中两个是“节点是否脱机”和“是否有足够的存储空间”。如果不可用项的数量太大,可能会导致选择不健康的数据节点,因此,必须保证一定数量的健康数据节点。
选择可用数据节点时,部分判断条件
错误日志关键字监控
部分常见错误监控(主要监控异常/错误),对应关键字:
IOException,NoRouteToHostException,SafeModeException,UnknownHostException。
未复制Block数
Collection Item:Unreplicated lock
Unreplicated lock当数据节点脱机且数据节点出现故障时,将生成大量正在同步的块。
FGC监控
采集项目:FGC
读/写成功率
Collection Items:
监视器_ Write.Status/Monitor _读取。状态
根据数据块的实际读/写流量聚合进行计算,这是外部SLA指标的重要基础。
数据盘故障
收藏项目:NumFailedVolumes
如果群集有1,000台主机,并且每台主机有12个磁盘(通用存储机器的标准配置),则这将是12,000个数据磁盘。根据机械磁盘的平均季度故障率1.65%(数据存储服务提供商Backblaze的统计数据),平均故障率为每月7个磁盘。如果集群规模进一步扩大,那么操作和维护工程师将在故障磁盘处理和服务恢复上花费大量精力。显然,迫切需要一套自动数据磁盘故障检测、自动修复和自动服务恢复机制。
除了监控故障磁盘,故障数据磁盘还必须有全局解决方案。在实践中,以场景为维度,通过自助解决问题。
 @
@
詹金斯基于场景的自助任务
2)流量
Block读、写次数
收集项目:
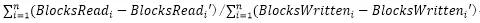 @
@
收集数据节点数据以进行聚合计算。
网络进出流量
收集项目:Node _ Network _ Receive _ Bytes _ Total/Node _ Network _ Transmit _ Bytes _ Total
没有可以直接使用的现成数据。它需要由接收字节(接收的总字节)和发送字节(发送的总字节)来计算。
磁盘I/O
收集项:node _ disk _ written _ bytes _ total/node _ disk _ read _ bytes _ total
3)延迟
RPC处理平均时间
收集项:RpcQueueTimeAvgTime
收集RpcQueueTimeAvgTime(RPC处理平均时间),SyncsAvgTime(日志节点同步耗时)。
慢节点数量
Collection Item:SlowpeeRePOrts
Slow节点的主要特点是落在节点上的读写与平均值相差很大,但只要给定足够的时间,仍然可以返回正确的结果。通常,慢速节点是由机器硬件和网络之外的相应节点上的大负载引起的。在实际监控中,除了监控节点上的读写时间,还需要监控节点上的负载。
根据实际需要,可以灵活调整数据节点报告时间,或者开启“陈旧节点”检测,使名称节点能够准确识别故障实例。涉及到一些配置项:
4)容量
集群总空间、空间使用率
采集项:PercentUsed
HDFS用户界面花费大量空间来显示存储空间的相关指标,这以说明其重要性。
空间使用计算包括“脱机”节点空间,这是一个陷阱。如果一些节点离线,但是它们所代表的空间仍然是在总空间中计算的。如果离线节点太多,就会出现这样一种“奇怪的现象”:集群中还剩下很多空间,但是没有写空间。
此外,在规划数据节点空间时,应该保留一些空间。HDFS保留的空间可能被其他程序或删除的文件使用,但它一直被引用。如果“未使用DFS”持续增加,需要跟踪和优化具体原因,并通过以下参数设置预留空间:
作为HDFS运维开发商,该公式需要明确:配置容量=总磁盘空间-预留空间=剩余空间未发布。
Namenode堆内存使用率
收集项目:
HeapMemoryUsage.used/HeapMemoryUsage.committed
如果将此指标作为HDFS的核心指标,就不算太多。元数据和块之间的映射关系占据了命名节点的大部分堆内存,这也是HDFS不适合存储大量小文件的原因之一。过多的堆内存使用可能会导致名称节点启动缓慢和潜在的FGC风险。因此,需要监控堆内存的使用情况。
事实上,堆内存的利用率提高了,这是不可避免的,并且给出了几种有效的解决方案:
虽然这些措施可以长期有效地降低风险,但是也有必要提很好地规划集群。
数据均衡度
收集项目:
HDFS,数据存储平衡在一定程度上决定了其安全性。实际上,这组数据的标准偏差是根据每个存储实例的空间利用率来计算的,以反馈每个实例之间的数据平衡程度。
当数据很大时,数据均衡将会很耗时,尽管很难通过调整并发性和速度来快速完成数据均衡。鉴于这种情况,我们可以尝试优先考虑离线空间已经用尽的情况,然后扩大容量以实现均衡的目标。
还需要注意的是,在3.0版之前,数据均衡只能是节点之间的均衡,不能实现节点内不同数据磁盘的均衡。
RPC请求队列的长度
收集项:CallQueueLength(RPC请求队列长度)。
文件数量
collection item:FileTotal
与堆内存使用一起使用。每个文件系统对象(包括文件、目录和块的数量)至少占用150字节的堆内存。基于此,我们可以粗略估计一个名称节点可以容纳多少文件。根据文件数量和块数量之间的关系,块大小也可以优化。
下线实例数
Collection Item:当NumDecommissionDataNodes
HDFS集群规模较大时,实时掌握健康实例表明,定期修复故障节点并及时上线可以为公司节省一定的成本。
5)其他
除了上述主要指标之外,还需要添加常见的监控策略,如服务器、进程JVM和从属服务(动物园管理员、域名系统)。
四、HDFS监控落地
Grafana仪表板显示主要用于维修检查和故障定位(说明:HDFS监控模板由Grafana正式提供,数据指标相对较少)。
HDFS部分集群Grafana仪表板
ELK-Hadoop:主要用于全局日志检索和错误日志关键字监控。搜索HDFS集群登录
日志服务搜索HDFS集群登录
顺化,HDFS用户界面:主要用于HDFS故障排除和日常维护。
五、HDFS案例
案例1:
DNS生成脏数据,导致名称节点高可用性失败。
案例2:
机架分组不合理,导致HDFS无法书写。
极牛网精选文章《阿里技术架构内部总结:HDFS监控落地的思考》文中所述为作者独立观点,不代表极牛网立场。如若转载请注明出处:https://geeknb.com/4735.html
 微信公众号
微信公众号  微信小程序
微信小程序 