糖化血红蛋白酶是一种高度可靠、高性能、面向列且可扩展的分布式存储系统,适用于结构化存储。底层依赖于Hadoop的HDFS,利用HBase技术可以在廉价的PCServer上构建大规模结构化存储集群。因此,糖化血红蛋白酶广泛用于大数据存储解决方案。


为何使用HBase
(1)HBase的优点:
列可以动态增加,当该列为空时,不会存储任何数据,从而节省了存储空间。糖化血红蛋白酶自动拆分数据,因此数据存储自动具有水平可扩展性糖化血红蛋白酶可以为高并发读写操作提供支持。
(2)HBase的缺点:
不支持条件查询,只支持按行键查询糖化血红蛋白酶,不适合传统的事务处理程序或关联分析。不支持复杂查询,这在一定程度上限制了它的使用。但是,将它用于数据存储的优势也非常明显
因为HbASe存储松散的数据,如果数据表的每行结构在您的应用程序中不同,您可以考虑使用HbASe。
因为糖化血红蛋白酶的列可以动态增加,如果列为空,则不存储任何数据,如果需要频繁追加字段,并且大多数字段为空,则可以考虑糖化血红蛋白酶。
因为HBase可以根据Rowkey提供高效的查询,如果您的数据(包括元数据、消息、二进制数据等。)具有相同的主键,或者您需要通过键访问和修改数据,使用HBase是一个不错的选择。
二、如何使用HBase
场景一:卖家操作日志
seller operation log,顾名思义,是一个用来记录商户操作的系统,从而确保商户能够准确查询其各种操作。JD.com有成千上万的商家一直在进行各种操作,所以卖家的操作日志具有数据量大、实时性强、搜索越来越少的特点。
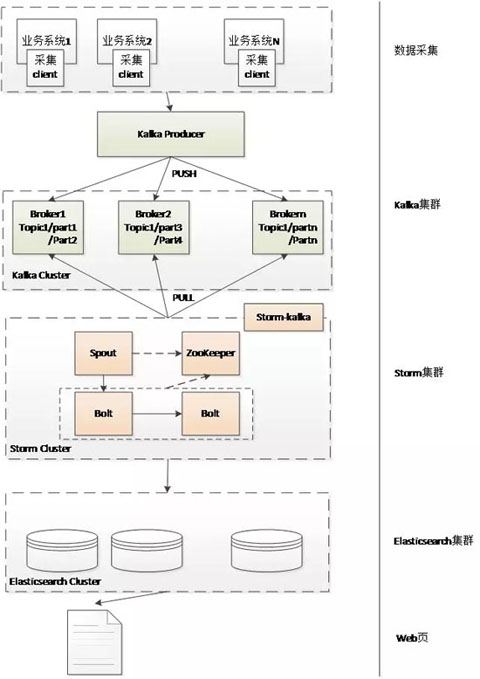
图1
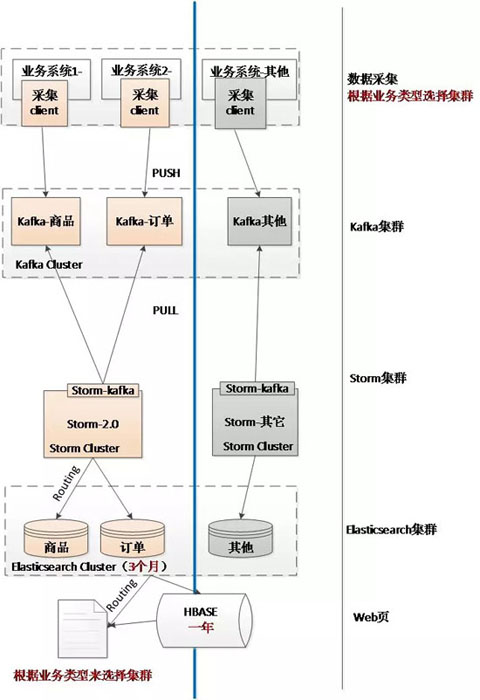
场景二:京麦消息日志的存储
在卖方操作日志的开头,所有操作日志都存储在ES中。操作日志中的数据量非常大,但当时可用的专家系统资源有限。当大量数据存储在有限的专家系统群集中时,性能会下降。在这种情况下,只有最近三个月的数据存储在专家系统集群中,以提供灵活的查询,而长期数据存储是通过使用糖化血红蛋白酶进行的。这样,可以实现最近操作的灵活显示和长期数据的精确备份。
1. Row Key
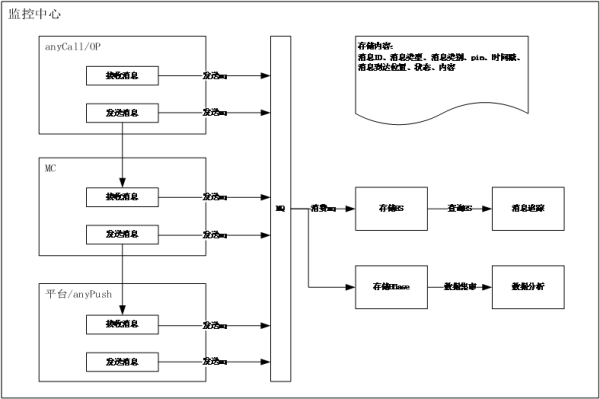
荆迈消息日志的存储是荆迈筋斗云系统(用于创建荆迈消息生态系统的闭环)不可或缺的一部分,包括消息的全链接跟踪和消息的统计分析。北京小麦每天都有数千万条信息。如何跟踪和统计信息已经成为一个关键问题。
邮件跟踪需要实时和多维精确的查询,因此选择在专家系统中存储最近一周的邮件日志。统计分析需要足够的数据,因此数据存储在ES和HBase中。最后,HBase中的数据会定期导入京东的数据集市,这样对京迈新闻进行统计分析就非常方便。
HBase的数据结构
2. Column Family
要使用HBase,您必须首先了解HbASe的数据结构:
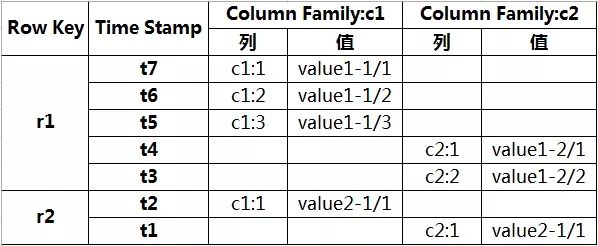
HBase存储一系列行记录,这些记录有三种基本类型的定义:行键、时间戳、列族。
3. Time Stamp
像NoSQL数据库一样,行键是用于检索记录的主键。访问HBase表中的行只有三种方式:
存储时,数据根据行键的字典顺序进行排序和存储。在设计密钥时,我们应该对这个特性进行完全排序和存储,并存储经常一起读取的行(位置相关性)。
三、简述HBase的架构原理
1. HBase的模块
HBase中的每个单元存储单元都有相同数据的多个版本,每个版本之间的差异根据唯一的时间戳来区分。不同版本的数据按相反的时间顺序排序,数据版本* * * *排名第一。
2. HBase的原理
四、使用HBase时应注意的问题

(1)master
HBA semaster用于协调多个区域服务器,检测每个区域服务器之间的状态,以及平衡区域服务器之间的负载。糖化血红蛋白主机还负责将区域分配给区域服务器。糖化血红蛋白酶允许多个主节点共存,但这需要动物园管理员的帮助。但是,当多个主节点共存时,只有一个主节点提供服务,其他主节点处于待机状态。当工作的主节点关闭时,其他主节点将接管HBase群集。
(2)区域服务器
对于区域服务器,它包括多个区域。区域服务器仅管理表并实现读写操作。客户端直接连接到区域服务器,并进行通信以获取糖化血红蛋白中的数据。对于区域,它是存储糖化血红蛋白酶数据的真实位置,这意味着区域是糖化血红蛋白酶可用性和分布的基本单位。如果一个表很大,并且由多个cfs组成,则该表的数据将存储在多个区域中,并且每个区域中将关联多个存储的单元格。
(3)动物园管理员
对糖化血红蛋白而言,动物园管理员的角色至关重要。第一动物园管理员是医管局的人身保护令。换句话说,动物园管理员保证至少有一个管理员在运行。动物园管理员负责注册区域和区域服务器。事实上,迄今为止,动物园管理员已经成为分布式大数据框架中容错的标准框架。不仅是糖化血红蛋白酶,几乎所有与分布式大数据相关的开源框架都依赖动物园管理员来实现高可用性。
五、总结
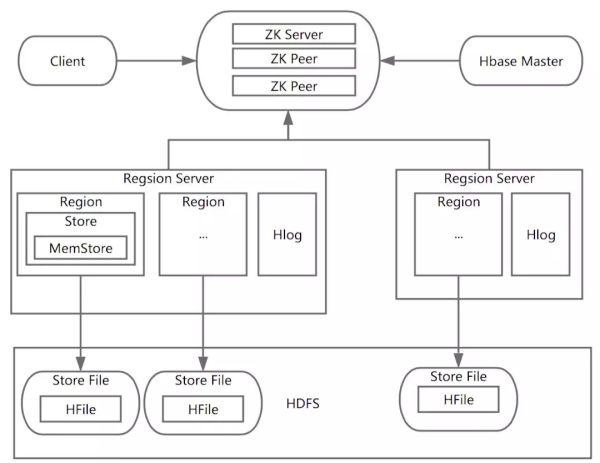
首先,我们需要知道HBase集群在机器之前是通过Zookeeper进行协调的,也就是说,HBase主机和区域服务器之间的关系是由Zookeeper维护的。当客户端需要访问糖化血红蛋白酶群集时,客户端需要在找到相应的区域服务器之前与动物管理员进行通信。每个区域服务器管理许多区域。对于糖化血红蛋白酶,区域是糖化血红蛋白酶并行化的基本单位。因此,数据也存储在该区域。
这里应该特别注意。每个区域仅存储列族的数据,并且是CF的一部分(根据行间隔分为多个区域)。一个区域可以存储的数据大小有一个上限。当达到上限(阈值)时,区域将被分割,数据将被分割成多个区域,这可以提高数据的并行性和数据的容量。
每个区域包多个商店对象。每个存储包含一个内存存储和一个或多个文件。MemStore是数据存储在内存中的实体,通常是有序的。当数据写入区域时,首先写入内存存储。当MemStore中的数据需要转储到底层文件系统时(例如,MemStore中的数据卷达到MemStore配置的* * *值),Store将创建StoreFile,这是HFile的封装层。因此,内存存储(MemStore)中的数据最终将被写入HFile,即磁盘IO。HFile存储在HDFS,因为糖化血红蛋白的底层依赖于HDFS。这是对整个糖化血红蛋白酶工作原理的简要描述。
在基于HBase的系统设计和开发中,要考虑的因素不同于关系数据库。糖化血红蛋白模式本身非常简单,但它给你更多的调整空间。有些模式具有良好的写入性能,但在读取数据时却表现不佳,相反,与传统数据库中的范式相似或基于范式建模,考虑到实际项目中的HBase设计模式是,我们需要从以下几个方面着手:
如今,各种数据存储方案层出不穷。结合两种实战场景,对基于糖化血红蛋白酶的大数据存储进行了简单分析,并简要阐述了糖化血红蛋白酶的原理。如何更好地使用HBase,甚至如何选择* * *数据存储方案,仍然需要根据现场的需要进行分析和设计。
极牛网精选文章《基于HBase的大数据存储在京东的应用场景》文中所述为作者独立观点,不代表极牛网立场。如若转载请注明出处:https://geeknb.com/4102.html
 微信公众号
微信公众号  微信小程序
微信小程序 