01 机器学习模型不可解释的原因
几天前,在同行交流小组中,有一个话题在小组中被热烈讨论,那就是如何解释机器学习模型。因为在风力控制领域,除非得到很好的解释,否则模型不会被通过,这在银行中尤其常见,所以大多数同行将使用LR来建模。然而,有这么多机器学习的模型算法,不使用它们难道不是浪费吗?有些算法也非常有用,至少在效果方面是如此,比如XGBoost、GBDT、阿达波斯。

然后,一些学生会问为什么这些算法没有解释。事实上,是这样的。刚才提到的模型都是集成模型,都是由复杂的树结构组成的。对人类来说,我们很难直观地解释为什么这个顾客是腐烂的,以及什么特征导致他腐烂。
02 特征重要度方法盘点
事实上,像XGBoost这样的模型仍然是解释性的。我们经常看到人们使用信息增益和节点分裂数来衡量特性的重要性,但这真的合理吗?
在解释它是否合理之前,有两个概念需要推广:
1)一致性
是指模型的特征重要性,它不会因为我们改变特征而改变其重要性。例如,模型a中特征X1的重要性是10。如果我们对模型中的特征X2增加一些权重来增加其重要性,那么在重新计算重要性之后,特征X1的重要性仍然是10。不一致可能导致重要性更高的特征不如重要性较低的特征重要。
2)个体化
表示重要性的计算可以单独进行,而不需要一起计算整个数据集。
好吧,有了以上的理解,让我们看看当前计算特征重要性的常用方法:
1)Tree SHAP: shapley加法解释。基于博弈论和局部解释的统一思想,采用树集成和加法方法激活特征属性的形状值。
2)Saabas:个性化启发式属性归属方法。
3)mean(| Tree SHAP |):基于个性化启发式SHAP平均的全局属性方法。
4)Gain: gain,一种由Breiman等人提出的全局特征重要性计算方法,可以在XGBoost、scikit learn等包中调用。它是在分离过程中由给定特征引起的杂质减少,通常用于特征选择。
5)Split Count:指的是给定特征用于拆分的次数(因为它越重要,引用就越容易,这与引用的论文大致相同)。
6)Permutation:是排序排列,指随机排列某个特征。看看模型效果误差的变化。如果特征很重要,模型误差将发生很大变化。
其中,只有1-2和3-6属于个性化属于全局统计,也就是说,需要计算整个数据集。
为了一致性,我们有一个例子来证明:
有两个模型,模型A和模型B,其中模型A和模型B是完全一致的,但是当我们计算预测值时,我们强制将10个点添加到模型B的特征咳嗽中。如下图所示(单击查看大图):
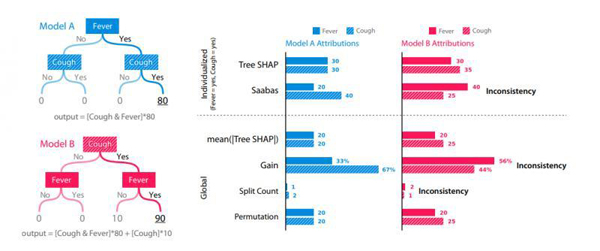
从实验结果中,我们可以看到以上六种方法的区别:
1)Saabas、Gain、Split Count均不满足 一致性 的要求,在改变了某个特征的权重之后,原先的特征重要度发生了改变,也直接导致重要度排序的改变。
2)而满足一致性要求的方法只有 Tree SHAP 和 Permutation了,而Permutation又是全局的方法,因此就只剩下了 Tree SHAP了。
03 SHAP可能是出路,SHAP到底是什么
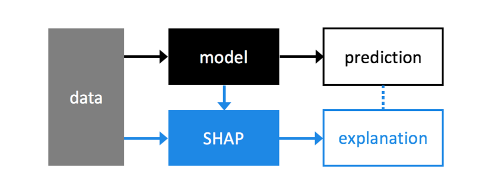
以上是官方定义。乍一看,我不知道该说些什么,但我可能得结合报纸来看。
definition 2.1 .输入特征的数量是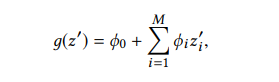
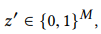
m,I ‘是特征的贡献。0是常数(指所有样本的预测平均值)。SHAP值有一个独特的解决方案和三个特征:局部精度、缺失、一致性。
1)Local Accuracy:局部精度,意味着每个特征的重要性之和等于整个函数的重要性
2)Missingness: missing,意味着缺少的值不会增加特征的重要性。
3)Consistency:一致性,这意味着改变模型不会改变特征的重要性。
简而言之,SHAP值可能是唯一能满足我们要求的方法,而XGBoost、GBDT等。上面提到的都是树模型,所以这里将使用树SHAP。
04 SHAP的案例展示
0401 SHAP的安装
的安装仍然非常简单。您可以通过终端的pip安装或conda安装来安装
pipinstall shapoorcondanstall-cconda-forgeshap
0402 对树集成模型进行解释性展示
output:
importXGBoostimportshap # LoadjsvisualizationcodetonOteBookshap . initjs()’ ‘训练xboost模型,相关数据集在SHAP”’ x,y=shap . dataset . Boston()模型=xbost . train(‘ learning _ rate ‘ 33600.01),xbost . dmatrix(x,label=y),100 ‘ ‘ ‘中提供’解释预测值树解释器(模型)SHAP值=解释器。SHAP _值(十)#视觉解释性(USEMATPLOTLIB=TREATO Operativascript)形状强制绘图(解释器.预期_值,形状_值[0,],[0,])

上图显示了每个特性的重要性。平均值将被预先计算,预测值将变得更高,有利于红色侧,而蓝色侧。
该数据集具有以下特征:“卷曲”、“锌”、“印度河”、“底盘”、“氮氧化物”、“RM”、“年龄”、“分布”、“弧度”、“税收”、“铂比”、“硼”、“LSTAT”
# #可视化训练集预测绘图.强制绘图(解释器.预期_值,形状_值,十)
上图显示了每个特征之间的相互作用(输出图是交互式的)。
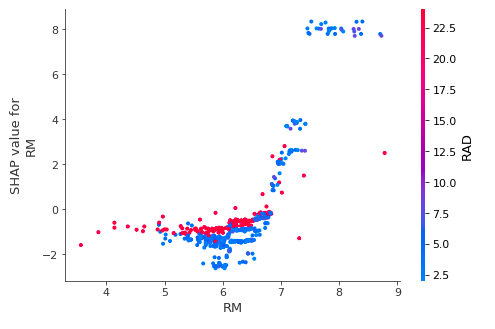
但是为了理解单个属性如何影响模型的输出,我们可以将该属性的SHAP值与数据集中所有样本的属性值进行比较。由于SHAP值代表了模型输出特性的变化,下图代表了预测房价的变化。
单个RM值的垂直离散表示与其他特征的相互作用。为了帮助揭示这些交叉依赖关系,dependence_plot会自动选择另一个要着色的要素。例如,RAD着色的使用突出表明,在RAD值较高的地区,RM(每户平均房间数)对房价的影响较小。

为了获得每个特征在整体级别上的重要性,我们可以为所有样本绘制所有特征的SHAP值,然后根据SHAP值的总和按降序对它们进行排序。颜色代表要素的重要性(红色代表高,蓝色代表低),每个点代表一个样本。
output:
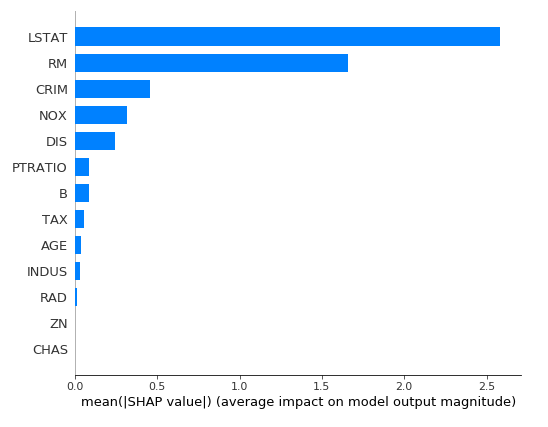
我们也可以只显示所有样本的平均值和SHAP值,并绘制一个条形图。
极牛网精选文章《如何解决机器学习树集成模型的解释性问题》文中所述为作者独立观点,不代表极牛网立场。如若转载请注明出处:https://geeknb.com/3351.html
 微信公众号
微信公众号  微信小程序
微信小程序 