你知道吗?甚至图像网也可能至少有100,000个标签。
在大量数据集中描述或发现标签错误本身就是一项具有挑战性的任务,许多男女主人公都很头疼。
最近,麻省理工学院和谷歌的研究人员提出了一种通用的自信学习(Confident Learning,CL)方法,可以直接估计给定标签和未知标签之间的联合分布。
这个通用CL也是一个开源的干净实验室Python包,它在ImageNet和CIFS上的性能比其他前沿技术高30%。
这个方法有多强大?拿一颗栗子。
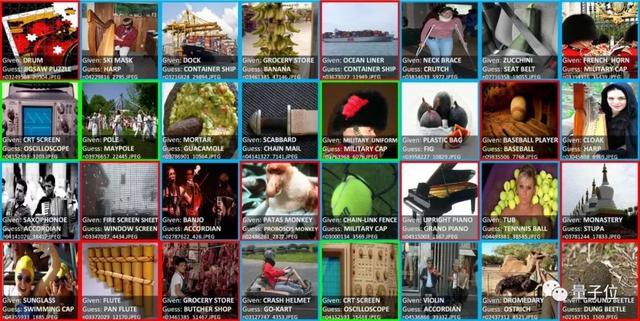
上图是2012年ILSVRC ImageNet训练集中使用自信学习发现的标签错误示例。研究人员将认知语言学发现的问题分为三类:“通过自信地学习,你可以在任何数据集中使用合适的模型来发现标签错误。下图是其他三个常见数据集的示例。
 @
@
△标签错误示例目前存在于亚马逊评论、MNIST和快速绘制数据集,这些数据集使用置信度学习来识别不同的数据模式和模型。
1,蓝色:图像中有多个标签;2.绿色:数据集应该包含一个类;3.红色:错误的标签。
这么好的方法,你不是很快就来品尝吗?
什么是自信学习?
自信学习已经成为监督学习的一个子领域。
从上图不难看出,CL需要2个输入:
对于弱监控,CL包括3个步骤:
CL的工作原理是什么?
 @
@
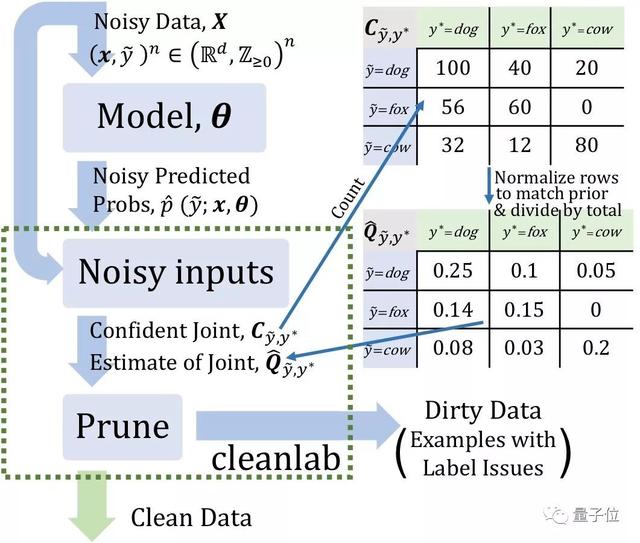
让我们假设有一个包含狗、狐狸和奶牛图像的数据集。CL的工作原理是估计噪声标签和真实标签的联合分布(下图右侧的Q矩阵)。
△左:置信度示例;右图:三种数据集的噪声标签和真实标签的联合分布示例。
接下来,CL计算了100个标记为类狗的图像,它们很可能是“狗”,如上图左边的矩阵所示。
CL还统计了标记为狗的56幅图像,但很有可能属于狐狸,32幅图像标记为狗,但很有可能属于奶牛。
这背后的核心思想是,当样本的预测概率大于每个类的阈值时,我们可以自信地认为样本属于这个阈值的类。
此外,每个类别的阈值是该类别中样本的平均预测概率。
轻松上手Clean Lab
自信学习已经成为监督学习的一个子领域。
Clean Lab有以下优点:
速度快:单一、非迭代、并行算法(例如,在不到1秒的时间内就可以在ImageNet中发现标签错误);鲁棒性:风险最小化保证,包括不完全概率估计;通用性:适用于任何概率分类器,包括PyTorch、Tensorflow、MxNet、Caffe2、scikit-learn等。独特性:用于多类学习的唯一软件包,带有噪声标签或查找任何数据集/分类器标签错误。
1行代码会发现标签错误!
3行代码学习噪音标签!
接下来,清洁实验室在MNIST表演。在该数据集上可以自动识别50个标签错误。
原始MNIST训练数据集的标签错误由rankpruning算法识别。描述按顺序从左到右排列的24个最不自信的标签,并从上到下增加置信度(属于给定标签的概率),用青色表示conf。预测概率最高的标签是绿色的。明显的错误用红色表示。
极牛网精选文章《超好用的自信学习:1行代码查找标签错误,3行代码学习噪声标签》文中所述为作者独立观点,不代表极牛网立场。如若转载请注明出处:https://geeknb.com/2857.html
 微信公众号
微信公众号  微信小程序
微信小程序 