

在网上找到了一些例子,还有一些成熟的模型可以把声音转换成文本。例如,cloudspeed api,但您需要使用谷歌云平台的前提。
speech recognition
对于python这种非常成熟的胶水语言来说,在网上找到一些现成的工具包并不太难。GitHub上发现了一个神奇的包:语音识别
可以支持实时翻译,当然前提是机器上安装了麦克风的相关包;它还支持从语音文件中直接提取字符。通过语音识别,可以调用各种平台上的模型,如谷歌应用编程接口、CMU狮身人面像、微软必应语音、IBM语音到文本、智能艾等
离线转换
对于国内网络环境,谷歌应用编程接口不能用来将语音数据转换成文本文件,因为在调用这个包时,需要连接到谷歌。当然,你可以租一个国外的虚拟专用网来做这件事。
让我们来谈谈如何不用网络就能通过python将语音文件转换成文本。这里使用的软件包是sphinx,它是卡内基梅隆大学开发的一个大词汇量、非特定、连续的英语语音识别系统。
安装 sphinx
我的环境是ubuntu。
在安装sphinx之前,需要安装一些软件包。
imyin@developer : ~/Downloads/phinx $ LSB _ release-AnolsbmoduleSareavable .distributoried : Ubundescript 3360 Ubuntu 16。04 .3 ltsreere :16。04 oden ame : xenial
之后,您可以在相关网站上下载sphinxbase安装包,当然,您也可以在下载后直接在clone github
上解压缩该包。
修改文件名
tarzxpfsphinxbase-5prealpha.tar.gz
现在我们应该运行autogen.sh来生成Makefiles和其他脚本,以便以后编译和安装。
mvsphinxbase-5 realphansPinspinxbase Shinshbase AuthorsDocedent。shmakefile。amReadMe。mdsrcwin 32 autogen。嘘。gitLicensewPhinxBase/autogen。sh
从下面开始源安装
makesudomakeinstall
执行上述命令后,如果没有错误消息,说明安装已经成功,但是此时您的命令无法生效,并且在运行该命令时会出现此类错误。
imyin@development : ~/Downloads/phinx/sphinx base $ sphinx _ lm _ convert :错误而alodingsharedlibraries 3360 libs hinx base。所以。 cannotoPensharedObjectfile : OshchFileOrDirectory
您还需要系统加载目录/usr/local/lib。为了使系统能够在每次启动时自动加载,您可以修改系统配置文件ld.so.conf
sudoecho ‘/usr/local/lib ‘/etc/LD。所以。con fsudoldconfig
此时,您可以通过sphinx_lm_convert命令将模型DMP文件转换为bin文件。
SphinDMp-ozh _ cn。lm。bin@
以上代码行将中国模型DMP文件转换为bin文件。安装sphinx后,默认情况下只支持英语,并且在存储模型的路径下只有一个文件名是en-US。因此,这里需要添加一个处理中文的模型,相关文件可以在这个网站上下载。

在python中使用sphinx
如果您想在python中使用sphinx,您需要安装一些依赖包。
pipinstallpydub-U #负责将MP3文件转换为wav文件管道安装语音识别-U#负责将语音转换成文字sudo apt-QQ installbuild-essentialswiglibpulse-dev #为后面安装pocketsphinx做准备pipinstall-Upocketsphinx#为使用sphinxsudoapt-getinstalliav-tools #为解决在调用pydub时出现的警告:运行时间警告:不能tfindffmpegoravconv-默认关闭mpeg,但是不能工作警告(“不能tfindffmpegoravconv-默认关闭mpeg,但是不能工作“,运行时警告)
此时,ipython可以开始尝试该效果。
file _ path=’/home/imyin/Downloads/phinx/test _ data ‘ r=Sr . Recognizer()hello _ zh=Sr . AudioFile(操作系统)。路径。连接(文件路径,’ test.wav ‘)与ello _ zhassource 3360音频今天天气很
如您所见,此语音识别器已经生效。但是我说的是“今天太热了”
狮身人面像中的模型似乎不太准确,这只是一个简短的句子。让我们看看长句的效果。我录了村上春树《当我谈跑步时我谈些什么》的一段话。
那年7月,我独自去希腊跑马拉松,把原来的马拉松路线——改为——。为什么要反向跑?因为我一大早就从雅典市区出发,在道路堵塞和空气污染之前跑出了城市。如果我一路跑完马拉松,路上的交通会少得多,跑步会更舒服。这不是正式的比赛。你可以自己跑。当然,你不能指望任何交通管制。hello _ zh=Sr . AudioFIle(OS . path . join(file _ path,’ test2.wav ‘)与ello _ zhassource : audio=r . record(source)r . recognize _ sphinx(audio,language=’zh_CN ‘)南银洋接收球的唯一位置是希望猪能在土木工程中温暖地处理垃圾。他能成功吗?他停止了与印度尼西亚商业报纸的谈话,说他没有资格谈论这家工厂能在春天从雅典市区成功突破的那家。他试图重申,这不是20个团队之间的正常竞争,这可能会加强协调部门对直接前往马拉松和ayama山的禁令,但他自己并没有解释任何这样的共识,当然“
嗯,看到结果,我想我们可以用一个词:糟糕。有两个词可以形容:太糟糕了!
当然,我直接从网上下载了这个模型。训练中使用的语料库不太完整,因此测试中不可避免地会出现不准确。为了使模型更精确,需要继续用sphnix训练模型。
相关方法可以在官方网站上找到,也有相应的教程。感兴趣的朋友可以自己学习。
为什么我的ccuracy PoorspeechrecognitionacuracyisNotalwAysgreat”。totestspeechrecognitionyouneedtornrecognorederendereferencedatabasetseewh at appendoptimizeparameters。如果没有未知值的操作布局,第一件事应该是收集样本和测量认知准确性的数据库。您需要将Youneedtodumpspeechutterancesintowavfiles、write reference extfile和sedecodertodeodecidet。那一年的7月,我去了希腊。我的翻译是:计算我们使用世界校准工具从斯芬克斯林。测试数据库大小依赖于一个精确的未来10分钟的被转录的音频测试识别器。我是一个人从雅典跑到马拉松河的吗?哪条原始马拉松路线是直达雅典的马拉松,并想创下[纪录?签名:r.record(source,duration=None,offset=None)Doctstring 3360 recordsupto“duration”second sofault from“source”(一个“AudioSource”实例)开始将“offset”(or atthebeginningifnotspecified)转换为“AudioData”实例,并对其进行设置。如果“持续时间”未指定,则twillrecorduntil resumeraudioinput。
本文中提到的教程网站是https://cmusphinx.github.io/wiki/tutorialtuning/
Google API
使用谷歌应用编程接口处理语音识别非常准确,但是你需要连接到谷歌。以下是我在VPS中执行的代码。可以看出,它准确地把我的录音翻译成文字。
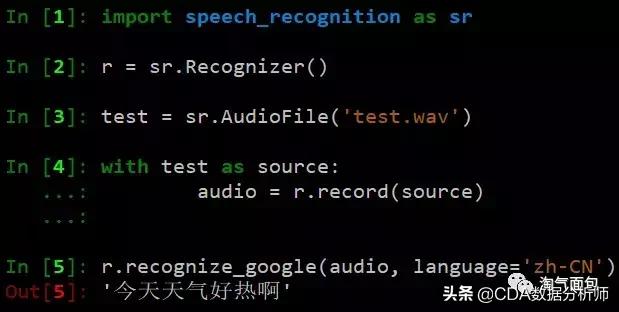
但是如果录制文件很大,将需要很长时间才能运行,并且会返回超时错误,这让我非常恼火。
幸运的是,语识别支持截取语音文件。例如,我只能处理语音文件的前15秒。
从以上结果来看,它比sphnix治疗简单得多。
查看帮助文档,发现语音识别不仅可以截取前一个录音,还可以截取中间的录音。
例如,我想处理5秒到20秒之间的内容。
今天就到这里。世界真的很精彩,更精彩,继续找你自己吧!
极牛网精选文章《教你怎样用Python进行语音识别》文中所述为作者独立观点,不代表极牛网立场。如若转载请注明出处:https://geeknb.com/2614.html
 微信公众号
微信公众号  微信小程序
微信小程序 