OpenResty × Open Talk 全国巡回沙龙是由 OpenResty 社区、又拍云发起,邀请业内资深的 OpenResty 技术专家,分享 OpenResty 实战经验,增进 OpenResty 使用者的交流与学习,推动 OpenResty 开源项目的发展。


王院生,APISIX 项目发起人和主要作者,OpenResty 社区、OpenResty 软件基金会发起人,《OpenResty 最佳实践》主要作者。
以下是分享全文:
首先做下自我介绍,我大学毕业后在传统金融行业工作九年,2014 年加入奇虎 360,期间撰写了《OpenResty 最佳实践》。我个人比较喜欢研究技术和开源,可能是受老罗影响,喜欢尝试理想化的事情。今年 3 月份与志同道合的伙伴一起创办了深圳支流科技公司,这是一家以开源方式创业的科技公司,在国内屈指可数,APISIX 是我们目前的主要项目。
APISIX 是微服务 API 网关产品,今年 7 月份我在上海做过一次关于“ APISIX 高性能实践”的分享,这次的内容是在上次分享的基础上,并会将最近的新积累分享给大家。
什么是 API 网关
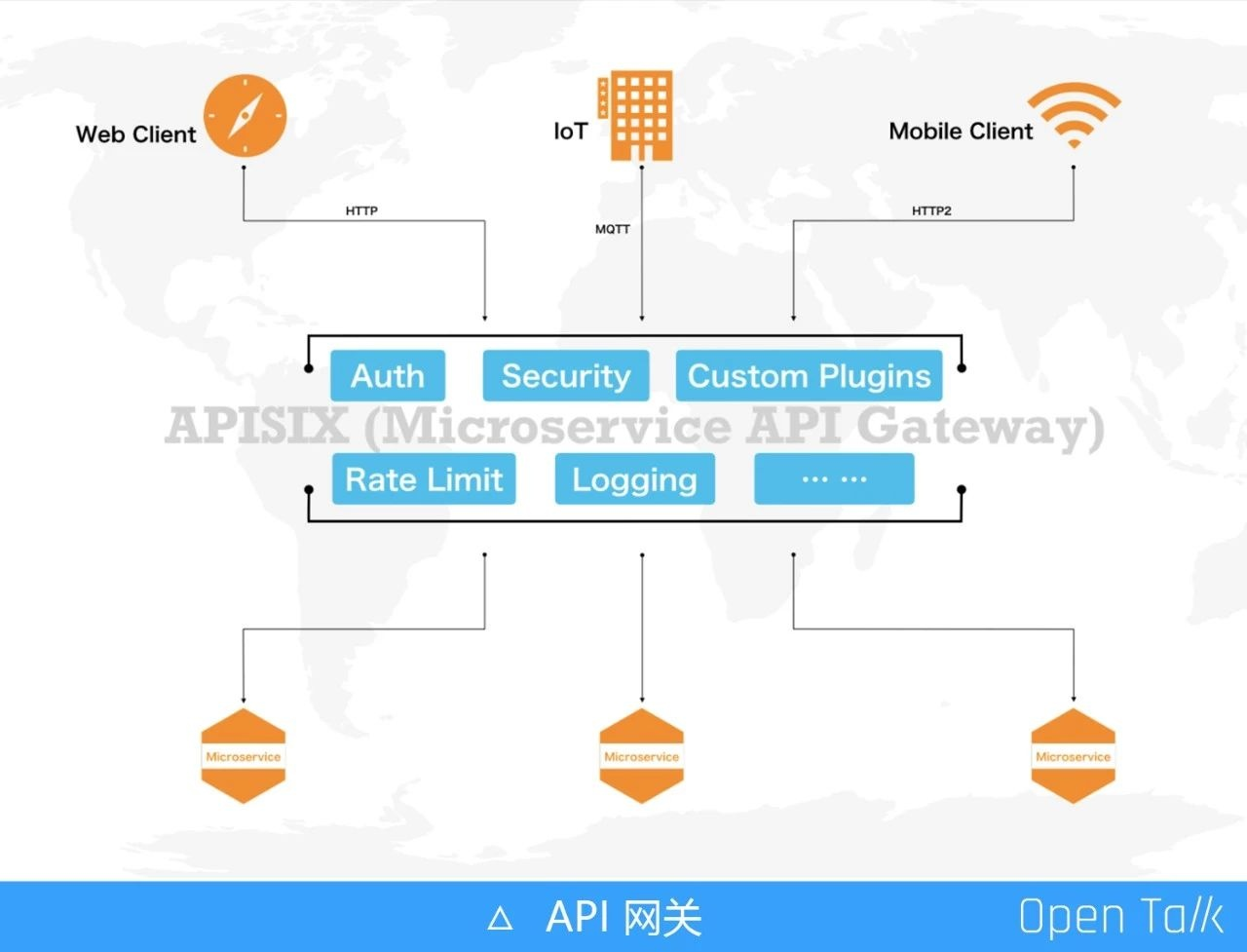
API 网关的地位越来越重要,它是所有流量的出入口,从图中可以看到请求方可能来自于浏览器、loT 设备以及移动设备等,API 网关作为中间管控层需要做安全控制、流量以及日志记录等。越来越多的企业采用了微服务的方式,以此完成内部解耦、灵活部署、弹性伸缩等技术特性从而满足业务需求。微服务的数量和复杂度也都随之水涨船高,通过 API 网关来完成统一的流量管理调度就非常必要,并对 API 网关提出了更高要求。
APISIX 概述

上图是 APISIX 的基本构架,由于要支持集群和高可用,所以在任何一个节点都需要包含 adminAPI 或 APISIX 内核,使用时可以只启用其中一部分或都启用。admin API 主要用于接收管理员的提交信息,通过 json schema 完成参数的校验,防止非法参数落到存储的配置中心。APISIX 内部部分处理外部请求,根据请求特征,匹配到具体路由规则,执行插件,然后把流量转发到指定上游服务。
APISIX 每个月会发布一个版本,在 0.7 版本支持了路由插件化,很自豪地说这是目前唯一允许自定义路由的 API 网关实现。除了之前已有的 r3 路由,APISIX 新增了专门高性能的前缀匹配 radixtree,radixtree 是由 Redix 的作者开源出来的。radixtree 代码的匹配效率是 r3 的 10 倍甚至更高,一些生产用户升级 radixtree 后 CPU 使用率确实下降明显。

上图显示的是两个月前 APISIX 已有的功能。

最近的两个月,APISIX 增加了以上新功能,每个月大概都会有 5、6 个大的新特性,如果我只准备 APISIX 里的一些新特性与大家分享,各位受益可能会比较小,所以今天我给大家分享一些通用的 OpenResty 编程技巧。
APISIX 主打的是高性能,我们与 OpenResty 对比性能,这样更能突出 APISIX 性能的极致。首先用 APISIX 完整服务来压测,对比一个没有任何功能的空 OpenResty 服务,发现 APISIX 在加载了所有功能的情况下只下降了 15% 的性能。换言之,你如果能接受 15% 的性能下降,就可以直接享受上图的所有功能。
OpenResty 优化技巧
路由:radixtree vs r3
既然已经有了 r3 ,为什么我们还要继续用 resty-radixtree 实现新的路由呢?
先介绍 r3 的问题:r3 的学习复杂度比较高(正则本身就有学习难度),并且不支持通过迭代器的方式迭代匹配结果,效率相比前缀树实现低不少。相反这些问题在 resty-radixtree 上都有完美解决方案,性能、稳定性自然也就提升很多。目前的 resty-radixtree 是基于 antirez/rax 实现的,也是 Redis 的作者写的,站在巨人肩膀可以让我们少走不少弯路。
从数据结构上看,前缀树理论上是比哈希算法更快,原因是哈希算法的真正复杂度是O(K),K 是指查询的 Key 的长度,Key 越长哈希算法把字符串变成整数就越复杂,而前缀树是层层递进,最坏的复杂度就是 O(K),因此前缀树的最坏效率与哈希算法是一样的。
当然这只是原理上的,经过专门测试发现 Lua table 的哈希查找速度秒杀前缀树,这是因为在编译 LuaJIT 的时候,它使用了 CPU 指令集来计算哈希值,这样可以完美的做到 O(1),所以 LuaJIT table 的哈希是效率是最高的,其次才是前缀树。
在 LuaJIT 世界匹配效率最高,永远都是先优先使用 Lua table 的哈希匹配。我们最终也没直接使用前缀树(trietree),因为它比较消耗内存,而是采用了基数树(radixtree),在性能相差不多的情况下,内存占用更小。
OpenResty VS Golang、HTTP VS gRPC
2015 年我没有选择 Golang 而选择 OpenResty,原因是我认为 OpenResty 可以思考地更深入,而 Golang 只能站在应用层去解决问题,出于这个原因我选择了 OpenResty。
APISIX 支持了这样一个场景:HTTP(s) -> APISIX -> gRPC server,把 REST API 转成 gRPC 请求。完成该功能后,需要做些压力测试验证效果。为了方便对比,用 Golang 的方式也写了一个协议转换网关。测试发现 APISIX 的版本比 Golang 的版本性能略还好一点,我的电脑上都是单核 1 万左右的 QPS。本以为在 gRPC 领域 Golang 的性能应当是最好的,没想到 APISIX 有机会略胜一筹。
我们之前粗浅地认为 HTTP 的性能一定没有 gRPC 的性能好,现在看有点武断。gRPC 的很多优势是 HTTP 不具备的,比如它的体积更小且内置 schema 检查等。但如果你的请求体比较小,在 HTTP 上使用 json 加 json schema,它们俩的性能几乎相同,尤其是在内网环境下相差还是非常小的。如果请求体比较大编码复杂,那么 gRPC 会有明显优势。

ngx.var 的加速
对获取 Nginx 变量的加速,最简单的就是用 iresty/lua-var-nginx-module 仓库,把它作为一个 lua module 编译到 OpenResty 项目里。当我们提取对应的 ngx.var 的时,使用库里提供的方法来获取,可以让 APISIX 整体有 5% 的性能提升,单纯某个变量性能对比,至少有 10 倍差别。当然也可以把这个模块编译成动态库,然后用动态方式加载,这样就不用重新编译 OpenResty。
APISIX 网关会从 ngx.var 里获取大量变量信息,比如 host 地址等变量更是可能会被反复获取,每次都与 Nginx 交互效率会比较低。因此我们在 APISIX/core 里加了一层 ctx 缓存,也就是第一次与 Nginx 交互获取变量,后面将直接使用缓存。
题外篇:再次推荐大家多参考借鉴 APISIX/core 中的代码,这些代码是通用的,对大多数项目都应该有借鉴意义。
fail to json encode
当我们用 json 的方式去 encode 一个 table时,可能会失败。失败原因有以下几种:比如 table 中包含 cdata 或者 userdata 无法 encode ,又或者包含 function 等,但实际上我们做 encode 并不是想要一个可以完美支持序列化/反序列化的结果,有时候只是为了调试。
所以我在 APISIX 的 core/json_encode 增加了一个布尔参数,表示是否进行强制转码,这样当遇到不能转码时就把强制它变成一个字符串。此外 table 套 table 是一个常见的情况,即有一个 table A,在 A 的 table 里面的内部又引用了A 自身,形成了一个循环嵌套。这个问题的解决比较简单,在发生嵌套时,到达某一个位置点后就不要再往里嵌了。这两个场景下允许强制 table encode 对我们开发调试非常有用。
在调试时,如果需要打一下 table 结果,当日志级别不够时,不应该触发无意义的 jsonencode 行为,这时候推荐使用 delay_encode 来调试日志,只有当日志真正需要写到磁盘上时,才会触发 json encode,避免那些不需要 encode 。这个问题在APISIX 里面效果非常好,终于不需要注释代码就可以完成不同级别日志的测试,有点 C 语言中宏定义的味道,对性能和易用是个极好的平衡。
静态代码检测工具
目前 APISIX 进行 CI 回归,都会运行代码检查工具进行检查:Lua -check 和 lj-releng。对当前代码目录的内容做静态检测,比如有没有加全局的变量,代码行的长度是不是超了等。
rapid json 的生命周期
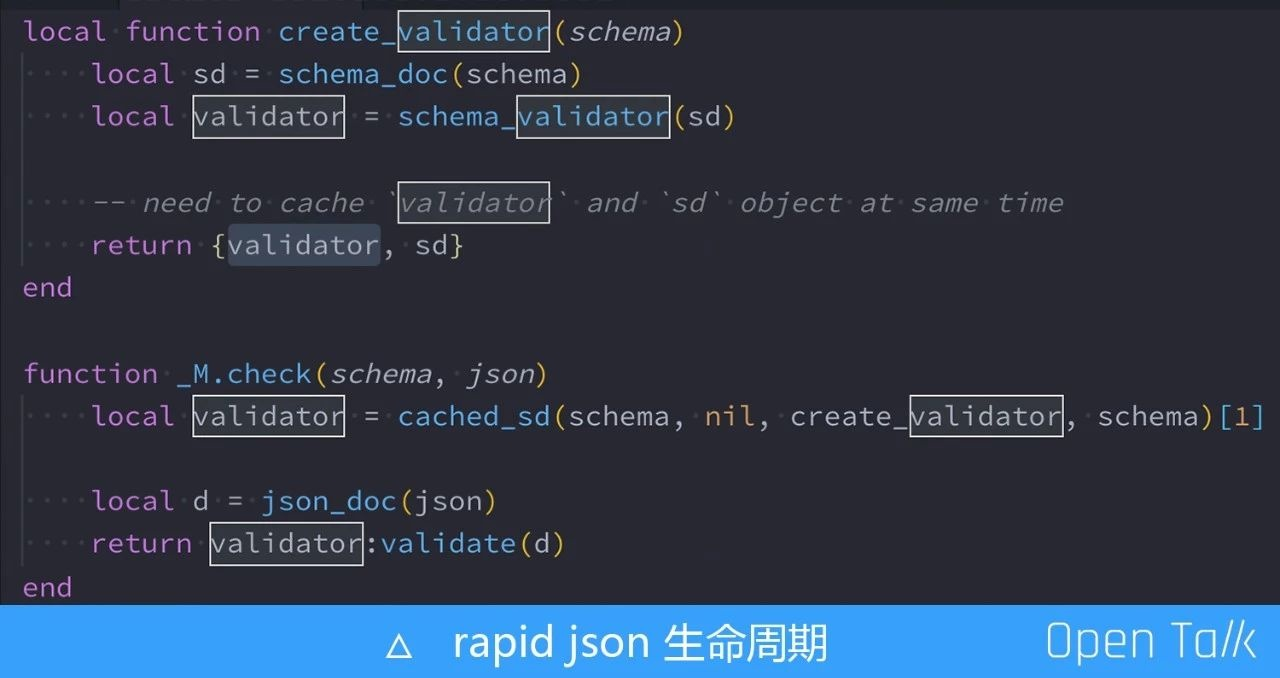
调试过程中发现的一个特别有意思的关于 rapid json 声明周期的 bug。关于这个周期的原因可以看一下上图的最后一行,我们真正使用的是 validator,而且只调用了validator 的一个验证,它是从上边的 create-validator 得来的。这里值得注意的是,为什么用一个数组缓存住另一个叫 sd 的对象呢?
因为 validator 是个 cdata ,内部有对 sd 对象的指针引用依赖,他们两个也就必须要有相同的声明周期,不能有某一项提前释放的情况。如果我们需要让两个对象有相同的生命周期,那么把它们放到同一个 table 中是最简单的方法。
第三方库使用 pcre
如果你选择效率最高的 C 库,而这个 C 库里还引用了 pcre 这个库,那就需要考虑到一个问题,这个对象的跨请求就会有非常大的风险,为此必须要单独给这个库创建独立的内存池,决不能使用当前请求的内存池,因为当前请求很快就被释放。
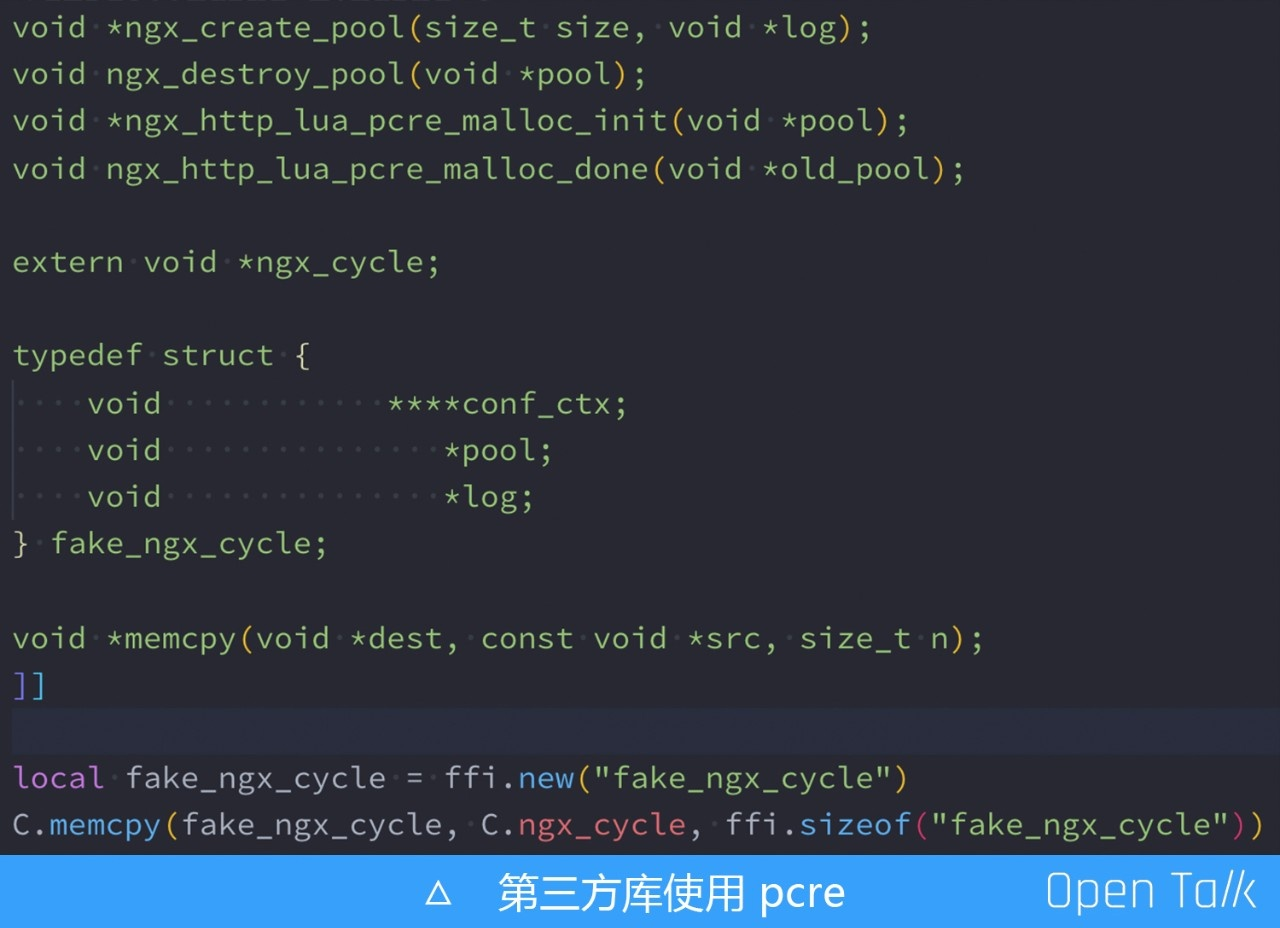
怎么解决这个问题呢?如果现在 OpenResty 有相关的 API,那么直接去申请内存池是最好的,但是可惜 OpenResty 并不具备。看看 Ningx 源码,可以看到创建 Nginx 的内存池函数定义是 ngx_create_pool(size_tsize, void *log) ,只要能获取到全局日志句柄即可。
我们选择从全局的 ngx_cycle 获取 log 对象,这里我定义了一个虚假的 fake_ngx_cycle 结构体,这个结构体和 Nginx 的 ngx_cycle 构体的前三项是一样的,但是截掉了后面的部分,然后我们做内存拷贝,从而得到了 log 对象指针位置。
开启 prometheus 插件
我当时在研究 Kong 的 prometheus 插件时粗略看了一下它的代码,发现他的实现逻辑是有问题的,会非常影响性能。所以没有直接使用 Kong 的方式,在 APISIX 中开启这个 插件,性能只会下降5% 左右。这个插件我们比 Kong 高近 10 倍性能。我也和 Kong 的技术负责人聊过这里,后续会把 APISIX 的一些做法贡献给 Kong,相互学习一起成长。
以上是我今天的全部分享,谢谢大家!
极牛网精选文章《再谈 APISIX 高性能实践》文中所述为作者独立观点,不代表极牛网立场。如若转载请注明出处:https://geeknb.com/11549.html
 微信公众号
微信公众号  微信小程序
微信小程序 